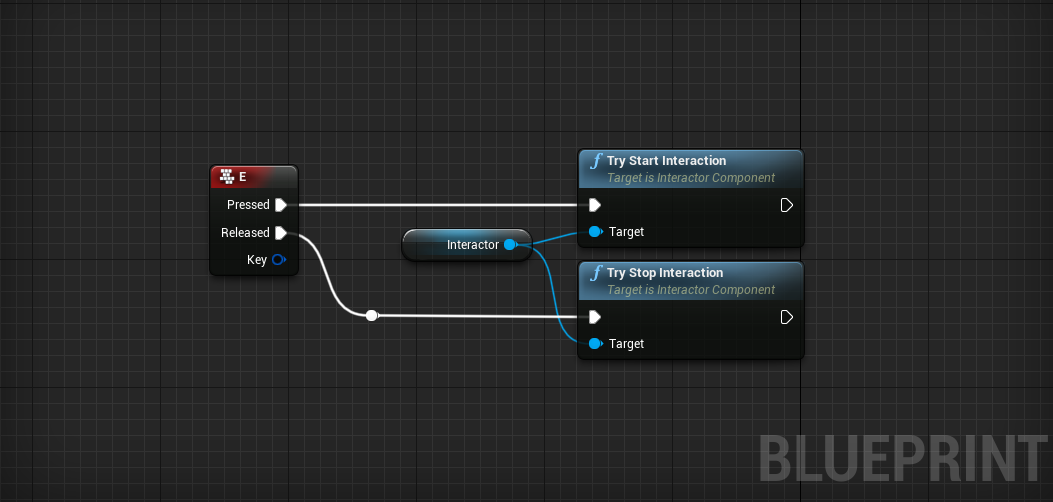
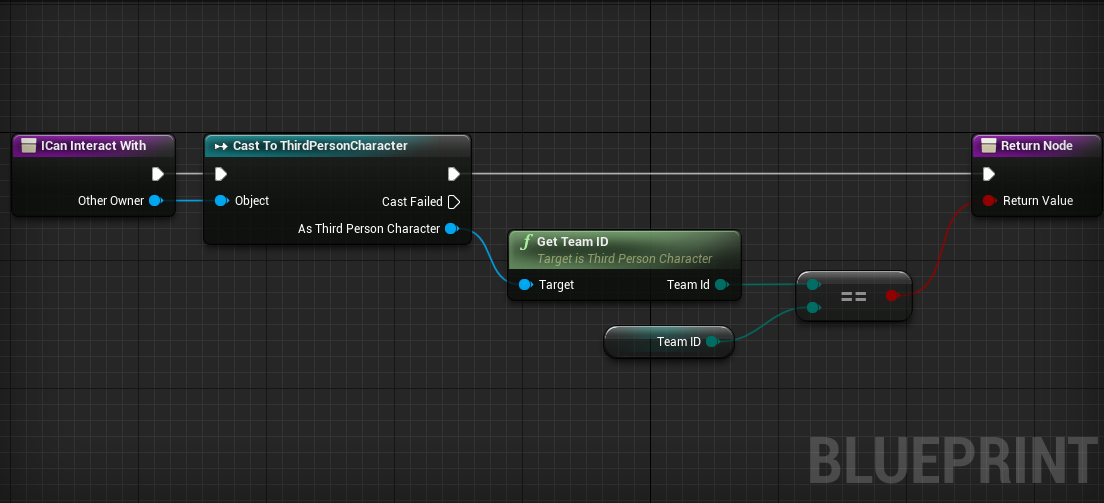
The Goal of this plug-in is to handle the interaction between player and objects/actors in the game by implementing a component based architecture. There are two main components, Interactor Component which is added to the player and Interaction Component for the Intractable Objects.
Introduction
The Interaction System is designed and developed based on a Component to Component communication architecture. All of the required logic during the interaction process is handled and processed by the components attached to the owners such as Characters and Interactive objects. The system is mainly made of two important components, Interactor Component which is added to the character or the player pawn and interaction component that is required by an interactive object.
Road map / Features:
Interaction Types
Instant [DONE]
Hold [DONE]
Condition Based Interaction
Single Interaction [DONE]
Multiple Interaction [DONE]
Custom Defined Condition E.g Team Id [DONE]
Multiplayer/Network Support
Interaction States Replication [DONE]
Interaction Process [DONE]
Notifications for Animations [DONE]
Documentation [DONE]
Showcase Level [DONE]
Getting up and Running
Add an Interactor Component to the Character or Player Pawn
Add an Interaction Component to the Interactive Object (e.g Door)
Setup an Input key to Invoke TryStartInteraction on the Interactor Component
Bind to the OnInteractorStateChanged Delegate on Interactor Component to Receive Interaction Results
Interaction Components
Class: UInteractionComponent
Interaction Component is added to an Interact-able object (E.g Doors,Pickup). There are currently two types of Interaction Components.
InteractionComponent_Instant:
Class: UInteractionComponent_Instant
Interaction is Instantly Completed upon Initiation by an Interactor.
InteractionComponent_Hold:
Class: UInteractionComponent_Hold
Hold Interaction is a Duration based interaction that requires the Interactor to actively interact with the object for the duration.
Multiple Interaction
Interaction Components can allow multiple interactions simultaneously. A configuration Boolean on the interaction component named bMultipleInteraction, controls and determines whether Interaction components can allow simultaneous interaction or only one interaction at a time. This does not imply to Instant interaction, as the interaction is completed instantly.
Condition Based Interaction
Class: IInteractionInterface
At times, Custom Conditions are required to be met before starting an interaction, for example, a lock system on a chest or team only buildings and equipment. In order to handle such custom conditions both Interactor and Interaction Components will Execute an Interface call on their owners ICanInteractWith(Actor* OtherOwner) Passing the other party actor, this interface then returns a Boolean determining whether the interaction can be initiated or not. ** However This does not mean that the interface has to be always implemented on the owner even if custom conditions are not required, the components will simply ignore the interface call if the owner does not implement it.**
E.g: In order to implement a team only chest, we simply add an Interaction Interface on the chest actor. Then we override the ICanInteractWith Function in the interface tab. Then inside the function, we get the team id of the OtherOwner then return true if the team id is equal to the chest team id.
Interaction Result
Both Interaction and Interactor Components implement Interaction Results and State. Interaction Results are enums that are meant to provide more information during the interaction process. These results are broadcasted through delegates when an Interaction is initiated up to completion.
Failed [IR_Failed]: Interaction Failed due to Conditions Returning False
Interrupted [IR_Interrupted]: Interaction Interrupted due to Player Pawn or Character Looking away and Going out of Reach during Interaction. Moreover, Interruptions Happen after removal of Interaction or Interactor Components during Interaction process.
These Interaction Results are received and broadcasted on Both Components through delegates (Blueprint Event Dispatcher).
Interaction Component: OnInteractionStateChanged
Interactor Component: OnInteractorStateChanged
In a networked Environments, These results are send to the clients through Remote Procedure Calls (RPC). But in Some cases this Information may not be relevant to all the clients or on the other hand, all the clients should be aware of these results. This can be controlled and configured on each component by changing the InteractorStateNetMode or InteractionStateNetMode.
None : None of the Clients Receive the Result Update
OwnerOnly : Only the Local Owner of the Component Will Receive the Update
All : All Clients With this Instance of the Component Will Receive the Update
Interaction Focus
It is important to be able to notify and inform the player of an interactive object or even show and interaction widget (Press E to Interact). This can be easily implemented by binding/listening to any of these delegates.
OnNewInteraction: This Delegate is broadcasted by the Interactor Component when a New Interactive object comes into the focus or leaves the reach of the player.
OnInteractionFocusChanged: Delegate Implemented by the Interaction Component. Broadcasted whenever the interaction object comes into the focus of a player.
Interaction Direction
In Some Cases, the direction of the interaction is important. Some Interactive Objects may require the Players to look at the face of the object in order to be able to interact. But for other interactive objects this may not be a requirement. This behavior can be configured on each Interaction Component Config setting by changing the Boolean variable named OnlyFaceInteraction. Setting this variable to true will require the player to look at the face of the object.
func (rf*Raft) AppendEntries(args*AppendEntriesArgs, reply*AppendEntriesReply) error {
idx:=0i:=0//prevLogIndex := args.PrevLogIndex - rf.lastIncludedIndex - 1offset:=args.PrevLogIndex-rf.lastIncludedIndexifoffset>0 {
/// offset > 0:需要比较第 offset 个 log 的 term,这里减1是为了弥补数组索引,lastIncludedIndex 初始化为 -1 也是如此offset-=1// if term of log entry in prevLogIndex not match prevLogTerm// set XTerm to term of the log// set XIndex to the first entry in XTerm// reply false (§5.3)ifrf.log[offset].Term!=args.PrevLogTerm {
reply.XTerm=rf.log[offset].Termforoffset>0 {
ifrf.log[offset-1].Term!=reply.XTerm {
break
}
offset--
}
reply.XIndex=offset+rf.lastIncludedIndex+1rf.resetTimeout()
returnnil
}
// match, set i to prevLogIndex + 1, prepare for comparing the following logsi=offset+1
} else {
// offset <= 0:说明log在snapshot中,则令idx加上偏移量,比较idx及其之后的logidx-=offset
}
}
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */intrdbSave(char*filename, rdbSaveInfo*rsi) {
chartmpfile[256];
charcwd[MAXPATHLEN]; /* Current working dir path for error messages. */FILE*fp;
riordb;
interror=0;
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp=fopen(tmpfile,"w");
if (!fp) {
char*cwdp=getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) ""for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
returnC_ERR;
}
rioInitWithFile(&rdb,fp);
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) ==C_ERR) {
errno=error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */if (fflush(fp) ==EOF) goto werr;
if (fsync(fileno(fp)) ==-1) goto werr;
if (fclose(fp) ==EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only * if the generate DB file is ok. */if (rename(tmpfile,filename) ==-1) {
char*cwdp=getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final ""destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
returnC_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty=0;
server.lastsave=time(NULL);
server.lastbgsave_status=C_OK;
returnC_OK;
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
returnC_ERR;
}
Create a group database groupXDatabase. You can clean the db you previously used and resue that.
This time each group should have a single git branch. Coordinate amongst yourselves by ensuring every next person pulls the code last pushed by a team mate. You branch will be checked as part of the demo. Branch name should follow the naming convention project/booksManagementGroupX
Follow the naming conventions exactly as instructed.
{
bookId: {ObjectId,mandatory,refstobookmodel},
reviewedBy: {string,mandatory,default'Guest',value: reviewer's name},
reviewedAt: {Date, mandatory},rating: {number, min 1, max 5, mandatory},review: {string, optional}}
User APIs
POST /register
Create a user – atleast 5 users
Create a user document from request body.
Return HTTP status 201 on a succesful user creation. Also return the user document. The response should be a JSON object like this
Return HTTP status 400 if no params or invalid params received in request body. The response should be a JSON object like this
POST /login
Allow an user to login with their email and password.
On a successful login attempt return a JWT token contatining the userId, exp, iat. The response should be a JSON object like this
If the credentials are incorrect return a suitable error message with a valid HTTP status code. The response should be a JSON object like this
Books API
POST /books
Create a book document from request body. Get userId in request body only.
Make sure the userId is a valid userId by checking the user exist in the users collection.
Return HTTP status 201 on a succesful book creation. Also return the book document. The response should be a JSON object like this
Create atleast 10 books for each user
Return HTTP status 400 for an invalid request with a response body like this
GET /books
Returns all books in the collection that aren’t deleted. Return only book _id, title, excerpt, userId, category, releasedAt, reviews field. Response example here
Return the HTTP status 200 if any documents are found. The response structure should be like this
If no documents are found then return an HTTP status 404 with a response like this
Filter books list by applying filters. Query param can have any combination of below filters.
* By userId
* By category
* By subcategory example of a query url: books?filtername=filtervalue&f2=fv2
Return all books sorted by book name in Alphabatical order
GET /books/:bookId
Returns a book with complete details including reviews. Reviews array would be in the form of Array. Response example here
Return the HTTP status 200 if any documents are found. The response structure should be like this
If the book has no reviews then the response body should include book detail as shown here and an empty array for reviewsData.
If no documents are found then return an HTTP status 404 with a response like this
PUT /books/:bookId
Update a book by changing its
title
excerpt
release date
ISBN
Make sure the unique constraints are not violated when making the update
Check if the bookId exists (must have isDeleted false and is present in collection). If it doesn’t, return an HTTP status 404 with a response body like this
Return an HTTP status 200 if updated successfully with a body like this
Also make sure in the response you return the updated book document.
DELETE /books/:bookId
Check if the bookId exists and is not deleted. If it does, mark it deleted and return an HTTP status 200 with a response body with status and message.
If the book document doesn’t exist then return an HTTP status of 404 with a body like this
Review APIs
POST /books/:bookId/review
Add a review for the book in reviews collection.
Check if the bookId exists and is not deleted before adding the review. Send an error response with appropirate status code like this if the book does not exist
Get review details like review, rating, reviewer’s name in request body.
Update the related book document by increasing its review count
Return the updated book document with reviews data on successful operation. The response body should be in the form of JSON object like this
PUT /books/:bookId/review/:reviewId
Update the review – review, rating, reviewer’s name.
Check if the bookId exists and is not deleted before updating the review. Check if the review exist before updating the review. Send an error response with appropirate status code like this if the book does not exist
Get review details like review, rating, reviewer’s name in request body.
Return the updated book document with reviews data on successful operation. The response body should be in the form of JSON object like this
DELETE /books/:bookId/review/:reviewId
Check if the review exist with the reviewId. Check if the book exist with the bookId. Send an error response with appropirate status code like this if the book or book review does not exist
Delete the related reivew.
Update the books document – decrease review count by one
Authentication
Make sure all the book routes are protected.
Authorisation
Make sure that only the owner of the books is able to create, edit or delete the book.
In case of unauthorized access return an appropirate error message.
Testing
To test these apis create a new collection in Postman named Project 4 Books Management
Each api should have a new request in this collection
Each request in the collection should be rightly named. Eg Create user, Create book, Get books etc
Each member of each team should have their tests in running state
Refer below sample A Postman collection and request sample
{"_id": ObjectId("88abc190ef0288abc190ef55"),"title": "How to win friends and influence people","excerpt": "book body","userId": ObjectId("88abc190ef0288abc190ef02"),"ISBN": "978-0008391331","category": "Book","subcategory": "Non fiction","deleted": false,"reviews": 0,"deletedAt": "",// if deleted is true deletedAt will have a date 2021-09-17T04:25:07.803Z,"releasedAt": "2021-09-17T04:25:07.803Z""createdAt": "2021-09-17T04:25:07.803Z","updatedAt": "2021-09-17T04:25:07.803Z",}`
Reviews
{"_id": ObjectId("88abc190ef0288abc190ef88"),bookId: ObjectId("88abc190ef0288abc190ef55"),reviewedBy: "Jane Doe",reviewedAt: "2021-09-17T04:25:07.803Z",rating: 4,review: "An exciting nerving thriller. A gripping tale. A must read book."}
Response examples
Get books response
{status: true,message: 'Books list',data: [{"_id": ObjectId("88abc190ef0288abc190ef55"),"title": "How to win friends and influence people","excerpt": "book body","userId": ObjectId("88abc190ef0288abc190ef02")"category": "Book","reviews": 0,"releasedAt": "2021-09-17T04:25:07.803Z"},{"_id": ObjectId("88abc190ef0288abc190ef56"),"title": "How to win friends and influence people","excerpt": "book body","userId": ObjectId("88abc190ef0288abc190ef02")"category": "Book","reviews": 0,"releasedAt": "2021-09-17T04:25:07.803Z"}]}
Book details response
{status: true,message: 'Books list',data: {"_id": ObjectId("88abc190ef0288abc190ef55"),"title": "How to win friends and influence people","excerpt": "book body","userId": ObjectId("88abc190ef0288abc190ef02")"category": "Book","subcategory": "Non fiction","Self Help"],"deleted": false,"reviews": 0,"deletedAt": "",// if deleted is true deletedAt will have a date 2021-09-17T04:25:07.803Z,"releasedAt": "2021-09-17T04:25:07.803Z""createdAt": "2021-09-17T04:25:07.803Z","updatedAt": "2021-09-17T04:25:07.803Z","reviewsData": [{"_id": ObjectId("88abc190ef0288abc190ef88"),bookId: ObjectId("88abc190ef0288abc190ef55"),reviewedBy: "Jane Doe",reviewedAt: "2021-09-17T04:25:07.803Z",rating: 4,review: "An exciting nerving thriller. A gripping tale. A must read book."},{"_id": ObjectId("88abc190ef0288abc190ef89"),bookId: ObjectId("88abc190ef0288abc190ef55"),reviewedBy: "Jane Doe",reviewedAt: "2021-09-17T04:25:07.803Z",rating: 4,review: "An exciting nerving thriller. A gripping tale. A must read book."},{"_id": ObjectId("88abc190ef0288abc190ef90"),bookId: ObjectId("88abc190ef0288abc190ef55"),reviewedBy: "Jane Doe",reviewedAt: "2021-09-17T04:25:07.803Z",rating: 4,review: "An exciting nerving thriller. A gripping tale. A must read book."},{"_id": ObjectId("88abc190ef0288abc190ef91"),bookId: ObjectId("88abc190ef0288abc190ef55"),reviewedBy: "Jane Doe",reviewedAt: "2021-09-17T04:25:07.803Z",rating: 4,review: "An exciting nerving thriller. A gripping tale. A must read book."},]}}
Book details response no reviews
{status: true,message: 'Books list',data: {"_id": ObjectId("88abc190ef0288abc190ef55"),"title": "How to win friends and influence people","excerpt": "book body","userId": ObjectId("88abc190ef0288abc190ef02")"category": "Book","subcategory": "Non fiction","Self Help"],"deleted": false,"reviews": 0,"deletedAt": "",// if deleted is true deletedAt will have a date 2021-09-17T04:25:07.803Z,"releasedAt": "2021-09-17T04:25:07.803Z""createdAt": "2021-09-17T04:25:07.803Z","updatedAt": "2021-09-17T04:25:07.803Z","reviewsData": []}}
Functor theory – Explores the concept of exact categories and the theory of derived functors, building upon earlier work by Buchsbaum. Freyd investigates how properties and statements applicable to abelian groups can extend to arbitrary exact categories. Freyd aims to formalize this observation into a metatheorem, which would simplify categorical proofs and predict lemmas. Peter J. Freyd’s dissertation, presented at Princeton University (1960)
Algebra valued functors in general and tensor products in particular – Discusses the concept of valued functors in category theory, particularly focusing on tensor products. Freyd explores the application of algebraic theories in non-standard categories, starting with the question of what constitutes an algebra in the category of sets, using category predicates without elements. The text outlines the axioms of a group using category theory language, emphasizing objects and maps. Peter Freyd (1966)
Continuous Yoneda Representation of a small category – Discusses the embedding of a small category A into the category of contravariant functors from A to Set (the category of sets), which preserves inverse limits but does not generally preserve direct limits. Kock introduces a “codensity monad” for any functor from a small category to a left complete category and explores the universal generator for this monad. He demonstrates that the Yoneda embedding followed by this generator provides a full and faithful embedding that is both left and right continuous. Additionally, the relationship with Isbell’s adjoint conjugation functors and the definition of generalized (direct and inverse) limit functors are addressed, by Anders Kock (1966).
Abstract universal algebra – Explores advanced subjects in the realm of universal algebra. The core content is organized into two chapters, each addressing different aspects of universal algebra within the framework of category theory. The first chapter introduces the concept of triplable categories, inspired by the theory of modules over a ring, and explores the equivalence between categories of triples in any given category and theories over that category. In the second chapter, Davis shifts focus to equational systems of functors, a more generalized approach to algebra that encompasses both the triplable and structure category theories. Dissertation by Robert Clay Davis (1967)
A triple miscellany: some aspects of the theory of algebras over a triple – Explores the field of universal algebra with a particular focus on the concept of algebras over a triple. The work is grounded in the realization that categories of algebras, traditionally defined with finitary operations and satisfying a set of equations, can be extended to include infinitary operations as well, thereby broadening the scope of universal algebra. Manes starts by discussing the conventional understanding of universal algebra, tracing back to G.D. Birkhoff’s definition in the 1930s, and then moves to explore how this definition can be expanded by considering sets with infinitary operations. Dissertation by Ernest Gene Manes (1967)
Limit Monads in Categories – The work introduces the notion that the category of complete categories is monadic over the category of all categories, utilizing a family of monads associated with various index categories to define “completeness.” A significant portion of the thesis is dedicated to defining associative and regular associative colimits, arguing for their naturalness and importance in category theory. Dissertation by Anders Jungersen Kock (1967)
On the concreteness of certain categories – This work discusses the concept of concreteness in categories, stating that a concrete category is one with a faithful functor to the category of sets, and must be locally-small. He highlights the homotopy category of spaces as a prime example of a non-concrete category, emphasizing its abstract nature due to the irrelevance of individual points within spaces and the inability to distinguish non-homotopic maps through any functor into concrete categories. Peter Freyd (1969)
V-localizations and V-triples – This work focuses on two primary objectives within category theory. The first goal is to define and study Y-localizations of Y-categories, using a model akin to localizations in ordinary categories, involving certain conditions related to isomorphisms and the existence of unique Y-functors. The second aim is to explore the relationship between Y-localizations and V-triples, presenting foundational theories and examples to elucidate these concepts. Harvey Eli Wolff’s dissertation (1970)
Symmetric closed categories – This work is an in-depth exploration of category theory, focusing on closed categories, monoidal categories, and their symmetric counterparts. It discusses foundational concepts like natural transformations, tensor products, and the structure of morphisms, emphasizing their additional algebraic or topological structures. W. J. de Schipper (1975)
Algebraic theories – Covers topics such as the fundamentals of algebraic theories, free models, special theories, the completeness of algebraic categories, and extends to more complex concepts like commutative theories, free theories, and the Kronecker product, among others. The notes also touch on the rings-theories analogy proposed by F. W. Lawvere, suggesting an insightful correlation between rings/modules and algebraic theories/models. Gavin C. Wraith (1975)
Articles
Bayesian/Causal inference
A Categorical Foundation for Bayesian probability – Bayesian inference and decision making on measurable spaces with countably generated σ-algebras, using regular conditional probabilities and Eilenberg–Moore algebras by Jared Culbertson, Kirk Sturtz (2013)
A Channel-Based Perspective on Conjugate Priors – Introduces channels in a graphical language to define and study conjugate priors in Bayesian probability, and shows how they ensure the same class of distributions for prior and posterior by Bart Jacobs (2017)
A category theory framework for Bayesian Learning – Drawing from Spivak, Fong, and Cruttwell et al.’s foundational works, this study establishes a categorical framework for Bayesian inference, incorporating concepts of Bayesian inversions by Kotaro Kamiya, John Welliaveetil (2021)
Bayesian Open Games – Extends compositional game theory to handle stochasticity and incomplete information using category theory and coend optics by Joe Bolt, Jules Hedges, Philipp Zahn (2019)
Bayesian Updates Compose Optically – Utilizing lens pattern and a fibred category to model the compositional structure of Bayesian inversion by Toby St. Clere Smithe (2020)
Bayesian machine learning via category theory – Using categorical methods, the study frames machine learning concepts within the realm of conditional probabilities, building models for both parametric and nonparametric Bayesian reasoning on function spaces, and exemplifies the Kalman filter’s relation to the hidden Markov model by Jared Culbertson, Kirk Sturtz (2013)
Categorical Stochastic Processes and Likelihood – Explores the link between probabilistic modeling and function approximation, introduces two extensions of function composition related to stochastic processes by Dan Shiebler (2020)
Causal Inference by String Diagram Surgery – Extract causal relationships from correlations, using string diagram syntax and semantics, and showcases a method to compute causal effects by Bart Jacobs, Aleks Kissinger, Fabio Zanasi (2018)
Compositionality in algorithms for smoothing – Backward Filtering Forward Guiding with optics and prove that different ways of composing the building blocks of BFFG correspond to equivalent optics by Moritz Schauer, Frank van der Meulen, Andi Q. Wang (2025)
The Compositional Structure of Bayesian Inference – Examines how Bayes’ rule, which updates beliefs based on new evidence, can be applied piecewise to complex processes, linking it to the lens pattern in programming by Dylan Braithwaite, Jules Hedges, Toby St Clere Smithe (2023)
The Geometry of Bayesian Programming – A geometric interaction model for a typed lambda-calculus equipped with tools for continuous sampling and soft conditioning by Ugo Dal Lago, Naohiko Hoshino (2019)
Databases
Algebraic databases – Enhances traditional category-theoretic database models to better handle concrete data like integers or strings using multi-sorted algebraic theories by Patrick Schultz, David I. Spivak, Christina Vasilakopoulou and Ryan Wisnesky (2017)
Algebraic Model Management: A survey – We survey the field of model management and describe a
new model management approach based on algebraic specification by Patrick Schultz, David I. Spivak, and Ryan Wisnesky (2017)
Functorial data migration – A database language based on categories and functors, where a schema is depicted as a category and its instance as a set-valued functor by David I. Spivak (2012)
Data Types
Categories of Containers – Introduces containers as a mathematical model of datatypes with templated data storage, demonstrating their robustness under various constructions, including initial algebras and final coalgebras by Michael Abbot, horsten Altenkirch and Neil Ghani (2003)
Deep Learning
Backprop as Functor – Describes a category for supervised learning algorithms that search for the best approximation of an ideal function using example data and update rules by Brendan Fong, David I. Spivak, Rémy Tuyéras (2017)
Compositional Deep Learning – Category-theoretic structure for a class of neural networks like CycleGAN, using this framework to design a new neural network for image object manipulation, and showcases its effectiveness through tests on multiple datasets by Bruno Gavranović (2019)
Compositionality for Recursive Neural Networks – Simplified recursive neural tensor network model aligns with the categorical approach to compositionality, offering a feasible computational method and opening new research avenues for both vector space semantics and neural network models by Martha Lewis (2019)
Deep neural networks as nested dynamical systems – Argues that the common comparison between deep neural networks and brains is wrong, and proposes a new way of thinking about them using category theory and dynamical systems by David I. Spivak, Timothy Hosgood (2021)
Dioptics: a Common Generalization of Open Games and Gradient-Based Learners – Relationship between machine-learning algorithms and open games, suggesting both can be understood as instances of “categories of dioptics”. It expands on gradient-based learning, introducing a category that embeds into the category of learners (2019)
Learning Functors using Gradient Descent – A category-theoretic understanding of CycleGAN, a notable method for unpaired image-to-image translation by Bruno Gavranović (2020)
Lenses and Learners – Shows a strong connection between lenses, which model bidirectional transformations like database interactions, and learners, which represent a compositional approach to supervised learning by Brendan Fong, Michael Johnson (2019)
Neural network layers as parametric spans – Linear layer in neural networks, drawing on integration theory and parametric spans by Mattia G. Bergomi, Pietro Vertechi (2022)
Reverse Derivative Ascent – Reverse Derivative Ascent, a categorical counterpart to gradient-based learning techniques, formulated within the context of reverse differential categories by Paul Wilson, Fabio Zanasi (2021)
Differentiable Causal Computations via Delayed Trace – Causal computations in sequences using a category-theoretical model featuring a “delayed trace” operation, by applying an abstract form of backpropagation through time by David Sprunger, Shin-ya Katsumata (2019)
Functorial String Diagrams for Reverse-Mode Automatic Differentiation – String diagram calculus with hierarchical features to capture monoidal structures, develop an automatic differentiation algorithm for simply typed lambda calculus, and represent the diagrams as “hypernets” (2021)
Reverse Derivative Categories – Axiomatization of a category for reverse derivatives in machine learning, analogous to Cartesian differential categories for forward derivatives (2019)
Simple Essence of Automatic Differentiation – Simplified and generalized automatic differentiation in reverse mode (RAD) algorithm, derived from a clear specification by Conal Elliott (2018)
Towards formalizing and extending differential programming using tangent categories – This paper explores how a simple differential programming language can be interpreted using synthetic differential geometry, proving it can consistently integrate manifolds and certain functions, while detailing the necessary frameworks and structures, by Geoff Cruttwell, Jonathan Gallagher, and Ben MacAdam (2019)
Using Rewrite Strategies for Efficient Functional Automatic Differentiation – This paper integrates Automatic Differentiation (AD) with dual numbers in a functional programming language, using rewrite rules and strategy languages for optimization, aiming to efficiently combine differentiation accuracy with strategic optimization scheduling, supported by promising preliminary results from a micro-benchmark by Timon Böhler, David Richter, Mira Mezini (2023)
Dynamical Systems
A categorical approach to open and interconnected dynamical systems – This paper presents a comprehensive graphical theory for discrete linear time-invariant systems, expanding on classical signal flow diagrams to handle streams with infinite pasts and futures, introduces a new structural view on controllability, and is grounded in the extended theory of props by Brendan Fong, Paolo Rapisarda and Paweł Sobociński (2015)
Game Theory
A semantical approach to equilibria and rationality – This paper connects game theoretic equilibria and rationality to computation, suggesting that viewing processes as computational instances can offer new algebraic and coalgebraic methods to understand equilibrium and rational behaviors by Dusko Pavlovic (2009)
Compositional game theory – Open games offer a new foundation for economic game theory, enabling larger models through a compositional approach that uses “coutility” to represent games in relation to their environment, and can be visually represented with intuitive string diagrams, capturing key game theory outcomes by Jules Hedges, Neil Ghani, Viktor Winschel and Philipp Zahn (2016)
The game semantics of game theory – We reinterpret compositional game theory, aligning game theory with game semantics by viewing open games as Systems and their contexts as Environments; using lenses from functional programming, we then construct a category of ‘computable open games’ based on a specific interaction geometry by Jules Hedges (2019)
Graph Neural Networks
Asynchronous Algorithmic Alignment with Cocycles – Current neural algorithmic reasoners use graph neural networks (GNNs) that often send unnecessary messages between nodes; in our work, we separate node updates from message sending, enabling more efficient and asynchronous computation in algorithms and neural networks (2023)
Graph Convolutional Neural Networks as Parametric CoKleisli morphisms – We categorically define Graph Convolutional Neural Networks (GCNNs) for any graph and connect it to existing deep learning constructs, allowing the GCNN’s adjacency matrix to be treated globally, shedding light on its inherent biases, and discussing potential generalizations and connections to other learning concepts by Bruno Gavranović, Mattia Villani (2022)
Graph Neural Networks are Dynamic Programmers – Using category theory and abstract algebra, we dive deeper into the presumed alignment between graph neural networks (GNNs) and dynamic programming, uncovering a profound connection, validating previous studies, and presenting improved GNN designs for specific tasks, hoping to bolster future algorithm-aligned GNN advancements by Andrew Dudzik, Petar Veličković (2022)
Learnable Commutative Monoids for Graph Neural Networks – Using the concept of commutative monoids, we introduce an efficient O(logV) depth aggregator for GNNs, offering a balance between speed and expressiveness by Euan Ong, Petar Veličković (2022)
Local Permutation Equivariance For Graph Neural Networks – Our Sub-graph Permutation Equivariant Networks (SPEN) method improves graph neural networks’ scalability and expressiveness by focusing on unique sub-graphs, proving competitive on benchmarks and saving GPU memory by Joshua Mitton, Roderick Murray-Smith (2021)
Natural Graph Networks – We introduce the concept of naturality in graph neural networks, offering a broader and efficient design alternative to traditional equivariance, with our design showing strong benchmark performance by Pim de Haan, Taco Cohen, Max Welling (2020)
Sheaf Neural Networks for Graph-based Recommender Systems – Using Sheaf Neural Networks, we enrich recommendation systems by representing nodes with vector spaces, leading to significant performance improvements in collaborative filtering and link prediction across multiple datasets (2023)
Sheaf Neural Networks with Connection Laplacians – Using Riemannian geometry, we refine Sheaf Neural Network design, optimally aligning data points and reducing computational overhead, offering a bridge between algebraic topology and differential geometry for enhanced performance (2022)
Topologically Attributed Graphs for Shape Discrimination – We’ve developed attributed graphs that combine Mapper graph approximations with stable homology, enhancing shape representation and boosting classification results in graph neural networks (2023)
Linguistics
Free compact 2-categories – The paper introduces the notion of a compact 2-category, and gives some examples, such as the 2-category of monoidal categories, the 2-category of bimodules over a ring, and the 2-category of finite-dimensional vector spaces by Joachim Lambek and Anne Preller (2007)
Mathematical foundations for a compositional distributional model of meaning – Using vector spaces and Lambek’s Pregroup algebra, we derive sentence meanings from words, enabling comparisons. Our model visually represents sentence construction and can adapt to Boolean semantics by Bob Coecke, Mehrnoosh Sadrzadeh and Stephen Clark (2010)
The Frobenius anatomy of word meanings I: subject and object relative pronouns – We use vectors and Frobenius algebras in a categorical approach to understand the semantics of relative pronouns. Two models are introduced: a truth-based and a corpus-based approach by Mehrnoosh Sadrzadeh, Stephen Clark and Bob Coecke (2014)
Manufacturing
String diagrams for assembly planning – This paper introduces CompositionalPlanning, a tool that uses string diagrams to unify CAD designs with planning algorithms, optimizing assembly plans which are then tested in simulations, showcasing its efficiency in the LEGO assembly context by Jade Master, Evan Patterson, Shahin Yousfi, Arquimedes Canedo (2019)
Metric Space Magnitude
Approximating the convex hull via metric space magnitude – This paper introduces CompositionalPlanning, a tool that uses string diagrams to unify CAD designs with planning algorithms, optimizing assembly plans which are then tested in simulations, showcasing its efficiency in the LEGO assembly context by Glenn Fung, Eric Bunch, Dan Dickinson (2019)
Magnitude of arithmetic scalar and matrix categories – We create tools that build categories from data and operate using scalar and matrix math, identifying features similar to outliers in various systems like computer programs and neural networks by Steve Huntsman (2023)
Practical applications of metric space magnitude and weighting vectors – The magnitude of a metric space quantifies distinct points and its weighting vector, especially in Euclidean spaces, offers new algorithms for machine learning, proven through benchmark experiments (2020)
The magnitude vector of images – We explore the metric space magnitude in images, revealing edge detection abilities, and introduce an efficient model that broadens its use in machine learning (2021)
Generalized Petri Nets – We present Q-net, an extension of Petri nets using Lawvere theory Q, and offer a functorial approach to delineate their operational semantics across multiple net systems by Jade Master (2019)
The Mathematical Specification of the Statebox Language – The Statebox language is built on a solid mathematical foundation, synergizing theoretical structures for reliability; this document shares that foundation to aid understanding and auditing by Fabrizio Genovese, Jelle Herold (2019)
Probability and Statistics
A Convenient Category for Higher-Order Probability Theory – Quasi-Borel spaces improve higher-order probabilistic programming by supporting advanced functions and continuous distributions, offering better proof principles and refining core probability theory constructs (2017)
A Probability Monad as the Colimit of Spaces of Finite Samples – We introduce a probability monad for metric spaces, simplifying integration theory, and linking it to the category of convex subsets in Banach spaces by Tobias Fritz, Paolo Perrone (2017)
A categorical approach to probability theory – The paper introduces the Giry monad as a categorical tool for defining and studying random processes and related concepts by Michèle Giry (2016)
Bimonoidal Structure of Probability Monads – We examine joints, marginals, and independence in categorical probability using mathematical structures, exemplified by the Kantorovich monad by Tobias Fritz, Paolo Perrone (2018)
Categorical Probability Theory – We reinterpret probability measures categorically, linking them to specific mathematical structures and demonstrating their connection to the Giry monad, with a theorem on the integral operator provided by Kirk Sturtz (2014)
Causal inference by string diagram surgery – We use a categorical approach with string diagrams to understand causality, showcasing a method to compute interventions, exemplified by analyzing smoking’s effect on cancer by Bart Jacobs, Aleks Kissinger and Fabio Zanasi (2018)
Computable Stochastic Processes – We present a computable theory of probability, applying it to discrete-time systems and the Wiener process, grounded in Turing computation for clarity by Pieter Collins (2014)
De Finneti’s construction as a categorical limit – We recast de Finetti’s 1930s probability theorem using modern categorical language, linking it to the Giry monad’s Kleisli category and identifying the final exchangeable coalgebra by Bart Jacobs, Sam Staton (2020)
Infinite products and zero-one laws in categorical probability – We enhance Markov categories’ approach to probability, exploring infinite products and introducing generalized zero-one laws of Kolmogorov and Hewitt-Savage, applicable beyond traditional probability settings by Tobias Fritz, Eigil Fjeldgren Rischel (2019)
Information structures and their cohomology – We define information structures to model contextuality in classical and quantum domains, linking them to observables, and delve into information cohomology, emphasizing the role of specific entropies by Juan Pablo Vigneaux (2017)
Markov Categories and Entropy – We merge Markov categories with classic information theory, offering a fresh view on determinism, entropy, and encompassing various entropy indices by Paolo Perrone (2022)
Markov categories – We use Markov categories for a unified categorical view on key probability concepts, enabling a consistent approach across various probability theories, from discrete to Gaussian by Tobias Fritz (2019)
Set theory for category theory – This paper compares set-theoretic foundations for category theory, exploring their implications for standard categorical usage, tailored for those with minimal logic or set theory background by Michael A. Shulman (2008)
Topological Expressiveness of Neural Networks – This paper introduces a topological measure of a neural network’s expressive power, analyzing how it varies with architecture properties like depth and width by António Leitão (2020)
What is category theory, anyway? – Personal blog of Tai-Danae Bradley a research mathematician, explains concepts related to Category Theory and many other fields of math with illustrations in an accessible way
On compositionality – Personal blog of Jules Hedges a mathematics and computer science researcher affiliated
From design patterns to category theory – ploeh blog by Mark Seeman is his professional blog, where he writes about programming, software development, and architecture
The Topos Lab – The Topos Institute works to shape technology for public benefit by advancing sciences of connection and integration. Current research personnel includes Brendan Fong, John Baez and David Spivak
Books
Category Theory – This book offers an in-depth yet accessible introduction to category theory, targeting a diverse audience and covering essential concepts; the second edition includes expanded content, new sections, and additional exercises by Steve Awodey (2010)
Categories for the Working Mathematician – The content is in-depth, and its mathematical aspects can be challenging for the reader. It’s advisable to explore this book after reading one or two of the more introductionary books. This book is a classic by Saunders Mac Lane (1971)
Category Theory for Programmers – This book introduces Category Theory at a level appropriate for computer scientists and provides practical examples (in Haskell) in the context of programming languages by Bartosz Milewski (2019)
Category Theory for the Sciences – An introduction to category theory as a rigorous, flexible, and coherent modeling language that can be used across the sciences by David I. Spivak (2014)
Conceptual Mathematics: A First Introduction to Categories – This book demonstrates the power of ‘category’ to make mathematics easier and more connected for anyone. It begins with basic definitions and creates simple categories, such as discrete dynamical systems and directed graphs, with examples, by Schanuel, Lawvere (2009)
Draft of “Categorical Systems Theory” – This draft book is about categorical systems theory, the study of the design and analysis of systems using category theory by Jaz Myers (2022)
Polynomial Functors: A General Theory of Interaction – This book offers an interdisciplinary approach to the categorical study of general interaction, aiming to bridge diverse fields under a unified language to understand interactive systems; it provides detailed explanations and resources for learning, but assumes a foundational knowledge of category theory and graph-theoretic trees by Spivak, Niu (2023)
Seven Sketches in Compositionality: An Invitation to Applied Category Theory – This book by David I. Spivak and Brendan Fong (2019) provides an introductory glimpse into Category Theory by covering 7 key topics. It highlights practical, real-world examples to give readers a feel for the abstract theoretical concepts
The Joy of Abstraction – The book by Eugenia Cheng (2022) is written in a clear and engaging style. Cheng is a gifted writer who is able to make complex mathematical concepts accessible to a general audience
Basic Category Theory – Tom Leinster’s (2014) book represents an edited version of his lecture notes. As such, it is a concise work that provides focused coverage of the Category Theory topics it addresses
Category Theory in Context – This text book by Emily Riehl (2016) is advanced and is suitable for diligent students who have mastered prior readings. It’s praised for its well-crafted prose on Category Theory. Initially, it adopts an example-based methodology before illustrating how category theoretical language can encapsulate the concepts
Categories for Quantum Theory: An Introduction – Monoidal category theory provides an abstract language to describe quantum theory, emphasizing intuitive graphical calculus, and explores structures modeling quantum phenomena, classical information, and probabilistic systems, with connections to other disciplines highlighted throughout by Chris Heunen, Jamie Vicary (2020)
An Introduction to Category Theory – This book offers a beginner-friendly introduction to category theory, a versatile conceptual framework used across various disciplines, detailing fundamental concepts, examples, and over 200 exercises, making it ideal for self-study or as a course text, by Harold Simmons (2011)
Companies
Conexus – A start-up developing CQL, a generalization of SQL to data migration and integration that contains an automated theorem prover to rule out most semantic errors at compile time
Statebox – building a formally verified process language using robust mathematical principles to prevent errors, allow compositionality and ensure termination
IOHK – builds cryptocurrencies and blockchain solutions, based on peer reviewed papers; formally verified specifications in Agda, Coq and k-framework
RChain – blockchain ecosystem it’s foundational language – Rholang is implementation of rho-calculus wih deep roots in higher category theory and enriched Lawvere theories
Community
nForum – A discussion forum about contributions to the nLab wiki and related areas of mathematics, physics, and philosophy
ZulipChat – A Category Theory Zulip server, that requires invite
Compositionality – Open-access journal for research using compositional ideas, most notably of a category-theoretic origin, in any discipline
Theory and Applications of Categories – Theory and Applications of Categories (ISSN 1201 – 561X) is the all-electronic, refereed journal on Category Theory, categorical methods and their applications in the mathematical sciences.
What is Applied Category Theory – This is a collection of introductory, expository notes on applied category theory, inspired by the Applied Category Theory Workshop by Tai-Danae Bradley (2018)
18.S097: Programming with Categories, lecture notes – In this course we explain how category theory has become useful for writing elegant and maintainable code. In particular, we’ll use examples from the Haskell programming language to motivate category-theoretic constructs. By Brendan Fong, Bartosz Milewski, and David Spivak (2020)
Quantum Processes and Computation – Lecture Notes from Radboud University (Netherlands) by Aleks Kissinger and John van de Wetering (2019)
Category theory – Lecture Notes from University of Munich by Bodo Pareigis (2004)
Commutative algebra – This lecture is part of an online course on commutative algebra, following the book
“Commutative algebra with a view toward algebraic geometry” by David Eisenbud. By Richard E. Borcherds (2020).
Boston – This group is about applying category theory to problems in information management
New York – NYC Category Theory and Algebra is a group for people interested in studying Category Theory (CT) and/or Abstract Algebra together. One of our purposes is to meet and read basic texts in Category Theory.
San Francisco Bay Area – A meetup dedicated to teaching category theory, and especially applications, including functional programming, data management, block-chain, quantum computing, and AI.
Eric Daimler on Conexus and Category – Todays guest is CEO and co-founder of Conexus, the first spinoff of the MIT math department that takes discoveries in high level mathematics (category theory) and applies them to make databases intelligent across many industries (2022)
A Book of Abstract Algebra: Second Edition – Comprehensive yet approachable, this exceptional book covers all subjects addressed in a standard introductory abstract algebra course
Podcasts
Type Theory Forall – Podcast hosted by Pedro Abreu (Pronounced ‘Ahbrel’), PhD Student in Programming Languages at Purdue University
Lambda Cast – LambdaCast is a podcast about functional programming for working developers
The Catsters – Videos on various topics in category theory (2014)
Lenses, Folds, and Traversals – Talk from Edward Kmett (2012) at the second New York Haskell User Group Meeting on the new lens library, which provides a highly composable toolbox for accessing and modifying multiple parts of data structures
Category theory foundations – Steve Awodey has an excellent series, aimed a little higher (with a compsci flavour), going a little further
Category Theory Lecture 1 (NGA CoE-MaSS) – 2022 – This is a video-based course aimed at post-graduate students and as well academics interested to learn about category theory, with live participation of the audience shaping the content of the course. (2022)
Wiki
ncatlab – A wiki with content varying from pure category theory, to categorical perspectives on other areas of maths, to random unrelated bits of maths
Wikipedia – Has some good articles about category theory
This repository contains information about unStack Africa which is an Open Source Conference or technical meetups for the tech talent across the globe.
The unStack Virtual Conference hosted by unStack is focused towards empowering more developers throughout Africa and beyond in JavaScript, featuring world class speakers & core contributors to most used open source projects coming onboard to share their insights on things JavaScript.
You can register for the conference here Register.
Installation Guidelines
Fork this repo. Please be sure to use the current master branch as your starting point:
detects version increment by commit message keywords: fix: to increase path version, feat: to increase minor and !
or BREAKING CHANGE to increment major,
exposes tag, version and released output useful for docker image or package versioning,
after detection version increase creates GitHub release and gives the option to upload files as release assets.
Conventional commits
Conventional commits allow project versioning using keywords in the commit message.
The standard defines two specific keywords which presence in the commit message causes the version to increase: fix will increase path
and feat: minor version number. Increasing the major number is done by adding ! to any keyword e.g. refactor!: or
adding BREAKING CHANGE to the commit message.
The standard does not limit keywords apart from fix: and feat:, the following are common: build:, chore:, ci:, docs:, style:
, refactor:, perf:, test:.
Apart from the simple form of the keyword e.g. refactor:, it is possible to add the component affected by the change
e.g. refactor(payment): where payment is the component name.
Making the step execution dependent on the new version release:
# ...
- name: semverid: semver # required to use the output in other stepsuses: grumpy-programmer/conventional-commits-semver-release@v1env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: buildrun: make build
- name: docker buildrun: docker build -t my-repository/my-image
- name: docker pushif: ${{ steps.semver.outputs.released == 'true' }}run: | docker push my-repository/my-image
Using version
Version output from conventional-commits-semver-release could be used to add the version as a docker image tag:
# ...
- name: semverid: semveruses: grumpy-programmer/conventional-commits-semver-release@v1env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: buildrun: make build
- name: docker buildrun: docker build -t my-repository/my-image
- name: docker pushif: ${{ steps.semver.outputs.released == 'true' }} # check if a new version will be released# docker tag command is required to add version as the image tagrun: | docker tag my-repository/my-image my-repository/my-image:${{ steps.semver.outputs.version }} docker push my-repository/my-image:${{ steps.semver.outputs.version }}
Output could be set to env:
# ...
- name: docker pushif: ${{ steps.semver.outputs.released == 'true' }}env:
VERSION: ${{ steps.semver.outputs.version }} # setting version as env simplify usagerun: | docker tag my-repository/my-image my-repository/my-image:${VERSION} docker push my-repository/my-image:${VERSION}
The version and tag available in the output are set when declaring the action (main), release, and sending assets takes place after
successful completion of all steps and detection of a new version (post).
Input
input
type
default
description
init-version
string
0.1.0
initial version of the project
tag-prefix
string
v
tag prefix, useful for versioning multiple components in one repository
assets
multiline string
list of files to be upload as assets
Output
output
type
example
description
tag
string
v1.2.3
tag as tag-prefix + version
version
string
1.2.3
new version or current version if not released
version-major
string
1
major part of version
version-minor
string
2
minor part of version
version-patch
string
3
patch part of version
tag-prefix
string
v
tag prefix the same as input
released
bool
true
true if new version was released
Releasing actions with Conventional commits semver release
This project is an example of how to implement releasing Github Actions. The main challenge is to commit built in the pipeline javascript code and updating major version tag.
The media library for people who hate using their browsers. Built with Svelte, Tauri, and Sqlite.
Have you ever used sites like Letterboxd, Trakt, or Goodreads? There are plenty of web apps that do a great job of letting you track what media you consume, but they lack features for power users. myMedia is a cross-platform desktop app that lets you track your media consumption in a way that’s more powerful and customizable than any web app. Data is all stored locally, but should be syncable without much hassle using Syncthing or similar services, since it’s just SQlite.
Currently, I’m working on the very basics of getting a Tauri + Svelte app working; I’ve never used Rust or Svelte, so I might make some mistakes; bear with me.
I have a lot of long-term planning done already, at least for a v1.0.0 release and probably a v2.0.0 (v2 will probably be vector search, yet again something I have no experience with).
Features
Potential Future Features
Custom SQL queries? at your own risk, of course. (Similar to Obsidian Dataview)
Custom “Views” based on filter chains with custom columns and sorting (would also work with custom SQL)
Roadmap
(see the GitHub Project for a more detailed roadmap)
(these are STC)
v0.0.1: (pre-pre-alpha) Basic Tauri + Svelte app that can display data from an Sqlite database. Read-only
v0.1.0: Editable data (UI/UX should be good) and a browse page
v0.2.0: Basic search, filtering, and sorting
v0.3.0: Connect to APIs (OMDB, IMDB, TMDB, AniDB, etc.) to fetch data
v0.4.0: Per-episode/per-chapter notes and (potentially) ratings and tags for episodes/chapters
v0.5.0: Full-text search, maybe more advanced filtering
v0.6.0: Importing/Exporting data
v1.0.0: Finalize UX, make sure docs are thorough, etc.
v2.0.0: Vector Search
Priorities
Sprint 1
Basic frontend that mostly just shows off data, maybe no editing yet
Very basic backend that can serve data to frontend
Bugs:
Opening an external link in Tauri opens it in the same window instead of a browser.
Documentation
Installation
Note: Some features may require newer versions of WebKit or WebView2. I can’t guarantee support for older operating systems.
Full Docs
Contributing & Code Standards
Install js dependencies with pnpm install
Then, install the tauri cli: cargo install tauri-cli
Run with pnpm tauri dev
Testing & Code Coverage
8.5 seconds to run a single test? Playwright is just the best, isn’t it 🙂
Goal of this project is to provide a small, lightweight, understandable library to protect logins with passkeys, security keys like Yubico or Solo, fingerprint on Android or Windows Hello.
Manual
See /_test for a simple usage of this library. Check webauthn.lubu.ch for a working example.
Supported attestation statement formats
android-key ✅
android-safetynet ✅
apple ✅
fido-u2f ✅
none ✅
packed ✅
tpm ✅
Note
This library supports authenticators which are signed with a X.509 certificate or which are self attested. ECDAA is not supported.
Workflow
JAVASCRIPT | SERVER
------------------------------------------------------------
REGISTRATION
window.fetch -----------------> getCreateArgs
|
navigator.credentials.create <-------------'
|
'-------------------------> processCreate
|
alert ok or fail <----------------'
------------------------------------------------------------
VALIDATION
window.fetch ------------------> getGetArgs
|
navigator.credentials.get <----------------'
|
'-------------------------> processGet
|
alert ok or fail <----------------'
Attestation
Typically, when someone logs in, you only need to confirm that they are using the same device they used during
registration. In this scenario, you do not require any form of attestation.
However, if you need additional security, such as when your company mandates the use of a Solokey for login,
you can verify its authenticity through direct attestation. Companies may also purchase authenticators that
are signed with their own root certificate, enabling them to validate that an authenticator is affiliated with
their organization.
no attestation
just verify that the device is the same device used on registration.
You can use ‘none’ attestation with this library if you only check ‘none’ as format.
Tip
this is propably what you want to use if you want secure login for a public website.
indirect attestation
the browser may replace the AAGUID and attestation statement with a more privacy-friendly and/or more easily
verifiable version of the same data (for example, by employing an anonymization CA).
You can not validate against any root ca, if the browser uses a anonymization certificate.
this library sets attestation to indirect, if you select multiple formats but don’t provide any root ca.
Tip
hybrid soultion, clients may be discouraged by browser warnings but then you know what device they’re using (statistics rulez!)
direct attestation
the browser proviedes data about the identificator device, the device can be identified uniquely. User could be tracked over multiple sites, because of that the browser may show a warning message about providing this data when register.
this library sets attestation to direct, if you select multiple formats and provide root ca’s.
Tip
this is probably what you want if you know what devices your clients are using and make sure that only this devices are used.
Passkeys / Client-side discoverable Credentials
A Client-side discoverable Credential Source is a public key credential source whose credential private key is stored in the authenticator,
client or client device. Such client-side storage requires a resident credential capable authenticator.
This is only supported by FIDO2 hardware, not by older U2F hardware.
Note
Passkeys is a technique that allows sharing credentials stored on the device with other devices. So from a technical standpoint of the server, there is no difference to client-side discoverable credentials. The difference is only that the phone or computer system is automatically syncing the credentials between the user’s devices via a cloud service. The cross-device sync of passkeys is managed transparently by the OS.
How does it work?
In a typical server-side key management process, a user initiates a request by entering their username and, in some cases, their password.
The server validates the user’s credentials and, upon successful authentication, retrieves a list of all public key identifiers associated with that user account.
This list is then returned to the authenticator, which selects the first credential identifier it issued and responds with a signature that can be verified using the public key registered during the registration process.
In a client-side key process, the user does not need to provide a username or password.
Instead, the authenticator searches its own memory to see if it has saved a key for the relying party (domain).
If a key is found, the authentication process proceeds in the same way as it would if the server had sent a list
of identifiers. There is no difference in the verification process.
How can I use it with this library?
on registration
When calling WebAuthn\WebAuthn->getCreateArgs, set $requireResidentKey to true,
to notify the authenticator that he should save the registration in its memory.
on login
When calling WebAuthn\WebAuthn->getGetArgs, don’t provide any $credentialIds (the authenticator will look up the ids in its own memory and returns the user ID as userHandle).
Set the type of authenticator to hybrid (Passkey scanned via QR Code) and internal (Passkey stored on the device itself).
disadvantage
The RP ID (= domain) is saved on the authenticator. So If an authenticator is lost, its theoretically possible to find the services, which the authenticator is used and login there.
device support
Availability of built-in passkeys that automatically synchronize to all of a user’s devices: (see also passkeys.dev/device-support)
Goal of this project is to provide a small, lightweight, understandable library to protect logins with passkeys, security keys like Yubico or Solo, fingerprint on Android or Windows Hello.
Manual
See /_test for a simple usage of this library. Check webauthn.lubu.ch for a working example.
Supported attestation statement formats
android-key ✅
android-safetynet ✅
apple ✅
fido-u2f ✅
none ✅
packed ✅
tpm ✅
Note
This library supports authenticators which are signed with a X.509 certificate or which are self attested. ECDAA is not supported.
Workflow
JAVASCRIPT | SERVER
------------------------------------------------------------
REGISTRATION
window.fetch -----------------> getCreateArgs
|
navigator.credentials.create <-------------'
|
'-------------------------> processCreate
|
alert ok or fail <----------------'
------------------------------------------------------------
VALIDATION
window.fetch ------------------> getGetArgs
|
navigator.credentials.get <----------------'
|
'-------------------------> processGet
|
alert ok or fail <----------------'
Attestation
Typically, when someone logs in, you only need to confirm that they are using the same device they used during
registration. In this scenario, you do not require any form of attestation.
However, if you need additional security, such as when your company mandates the use of a Solokey for login,
you can verify its authenticity through direct attestation. Companies may also purchase authenticators that
are signed with their own root certificate, enabling them to validate that an authenticator is affiliated with
their organization.
no attestation
just verify that the device is the same device used on registration.
You can use ‘none’ attestation with this library if you only check ‘none’ as format.
Tip
this is propably what you want to use if you want secure login for a public website.
indirect attestation
the browser may replace the AAGUID and attestation statement with a more privacy-friendly and/or more easily
verifiable version of the same data (for example, by employing an anonymization CA).
You can not validate against any root ca, if the browser uses a anonymization certificate.
this library sets attestation to indirect, if you select multiple formats but don’t provide any root ca.
Tip
hybrid soultion, clients may be discouraged by browser warnings but then you know what device they’re using (statistics rulez!)
direct attestation
the browser proviedes data about the identificator device, the device can be identified uniquely. User could be tracked over multiple sites, because of that the browser may show a warning message about providing this data when register.
this library sets attestation to direct, if you select multiple formats and provide root ca’s.
Tip
this is probably what you want if you know what devices your clients are using and make sure that only this devices are used.
Passkeys / Client-side discoverable Credentials
A Client-side discoverable Credential Source is a public key credential source whose credential private key is stored in the authenticator,
client or client device. Such client-side storage requires a resident credential capable authenticator.
This is only supported by FIDO2 hardware, not by older U2F hardware.
Note
Passkeys is a technique that allows sharing credentials stored on the device with other devices. So from a technical standpoint of the server, there is no difference to client-side discoverable credentials. The difference is only that the phone or computer system is automatically syncing the credentials between the user’s devices via a cloud service. The cross-device sync of passkeys is managed transparently by the OS.
How does it work?
In a typical server-side key management process, a user initiates a request by entering their username and, in some cases, their password.
The server validates the user’s credentials and, upon successful authentication, retrieves a list of all public key identifiers associated with that user account.
This list is then returned to the authenticator, which selects the first credential identifier it issued and responds with a signature that can be verified using the public key registered during the registration process.
In a client-side key process, the user does not need to provide a username or password.
Instead, the authenticator searches its own memory to see if it has saved a key for the relying party (domain).
If a key is found, the authentication process proceeds in the same way as it would if the server had sent a list
of identifiers. There is no difference in the verification process.
How can I use it with this library?
on registration
When calling WebAuthn\WebAuthn->getCreateArgs, set $requireResidentKey to true,
to notify the authenticator that he should save the registration in its memory.
on login
When calling WebAuthn\WebAuthn->getGetArgs, don’t provide any $credentialIds (the authenticator will look up the ids in its own memory and returns the user ID as userHandle).
Set the type of authenticator to hybrid (Passkey scanned via QR Code) and internal (Passkey stored on the device itself).
disadvantage
The RP ID (= domain) is saved on the authenticator. So If an authenticator is lost, its theoretically possible to find the services, which the authenticator is used and login there.
device support
Availability of built-in passkeys that automatically synchronize to all of a user’s devices: (see also passkeys.dev/device-support)






 https://github.com/philippoehrlein/kirby-navigation-groups
https://github.com/philippoehrlein/kirby-navigation-groups