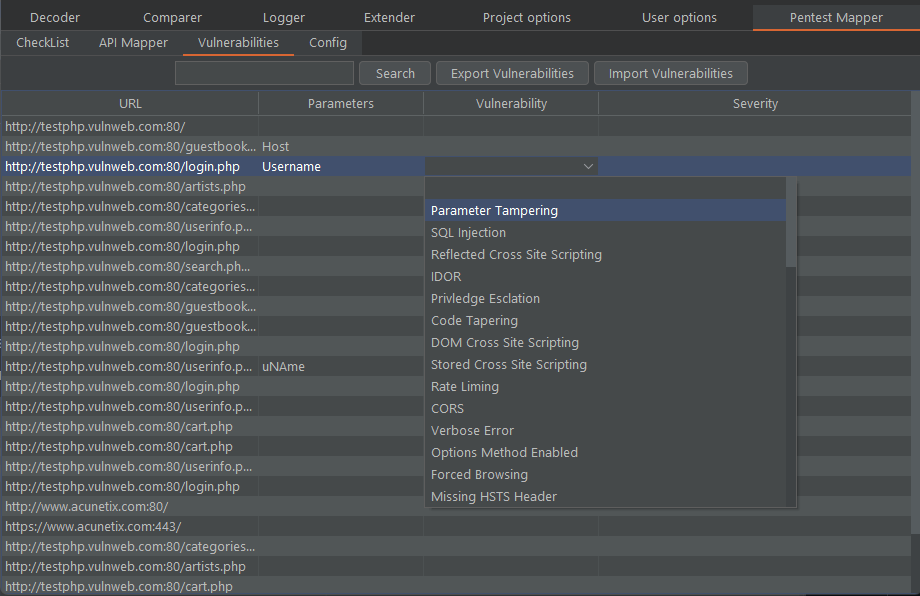
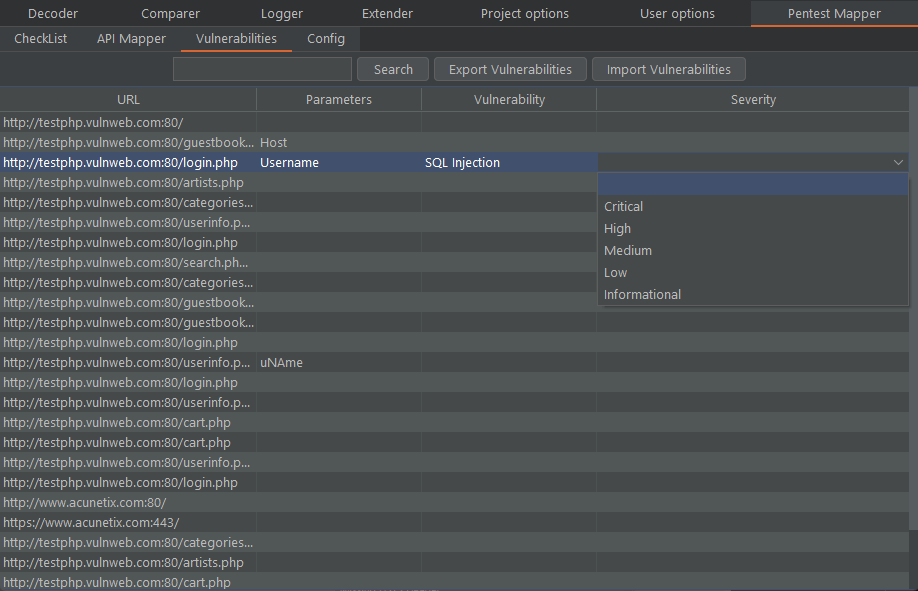
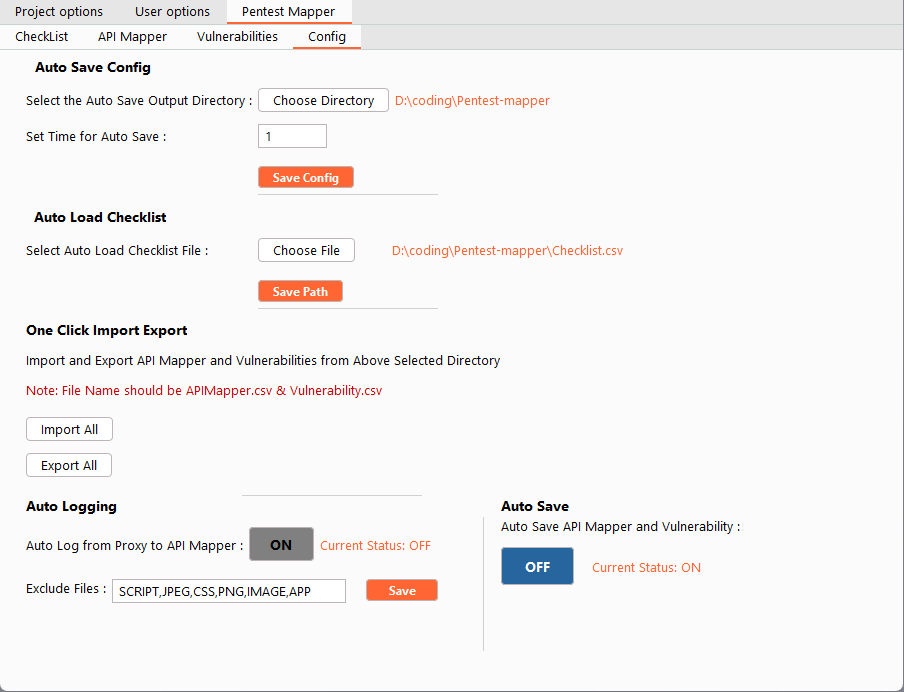
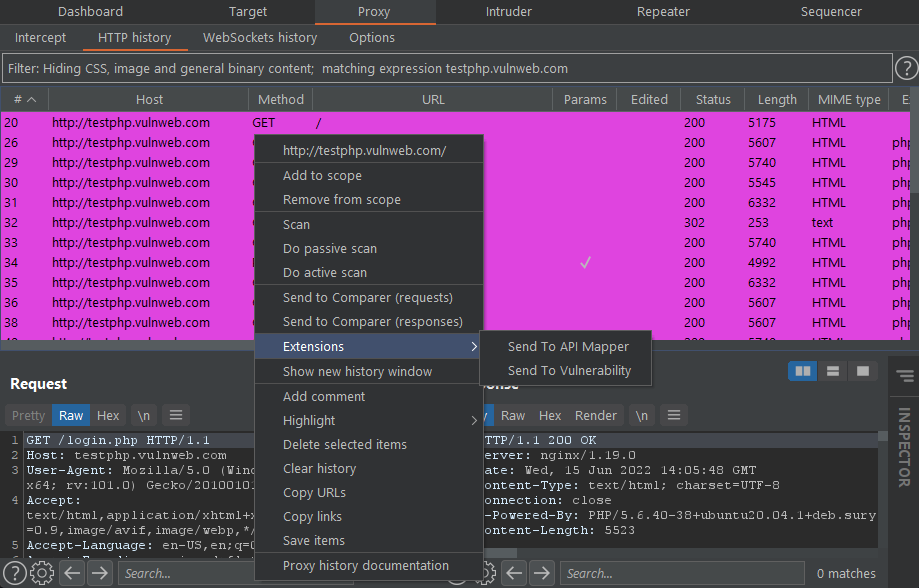
Starts a shell and logs it to a file. Requires bash, and either script or screen. Note: cat the log file back for full color.
See the latest instructions on the releases page
Usage: logshell.sh [-hvo] [-c {script|screen}] [-f <logfile>] [-s <shell>] [-e <file>]
Optional arguments:
-h Print this help message
-v Print the version number
-o Strip escape sequences (and color) from output
-e <file> Strip escape sequences from an existing file
-c [script|screen] Command to use (script or screen)
-f <logfile> Output file (try default)
-p <logpath> Output path (do not use with -f)
-s <shell> Shell to use (or command to execute)
-
Default output directory is
~/.local/log/logshell. -
Once you have logged a shell session, use ‘cat’ to view it in full color. Note: this is not recommended unless the output file has been formatted with the
-oor-eoption. -
If you set a command as your shell (with the -s option), logshell will execute it, log the output, and then exit. The following will start the quizlight program, log its output, and then log out of the system entirely so the test-taker can’t do any tampering:
logshell -s quizlight ; exit
# Note: This only works with commands that output to standard output.
-
Using logshell to capture trace output is a good development tool. Full output is captured, and can be compared to trace output from known working versions for debugging.
-
logshell can also be used to watch live tcpdump output and log it at the same time.

https://github.com/dogoncouch/logshell